Attention Recap, LLM Training and Generation
2026-02-10
Sources
Content derived from: J&M Ch. 8 (Transformers), Ch. 7 (Large Language Models)
Administrivia
- Project checkpoints due Thursday!
Learning Objectives
By the end of this lecture, you will be able to:
- Implement attention operations
- Explain the self-supervised pretraining objective for LLMs
- Describe what makes a Large Language Model “Large”
Recap: Attention Essentials
The Transformer architecture
![]()
Key components from last time:
- Self-attention with Q, K, V projections
- Multi-head attention for diverse relationships
- Causal masking for autoregressive generation
- Residual connections and layer normalization
Recall: Scaled dot-product attention
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V \]
- Q, K, V are linear projections of the input: \(Q = XW^Q\), \(K = XW^K\), \(V = XW^V\)
- Scaling by \(\sqrt{d_k}\) prevents softmax saturation
- Output for each position = weighted sum of all value vectors
Recall: Why scale by \(\sqrt{d_k}\)? Preventing softmax saturation
For random vectors \(\mathbf{q}, \mathbf{k} \in \mathbb{R}^{d_k}\) with entries ~ \(\mathcal{N}(0,1)\): \(\text{Var}(\mathbf{q} \cdot \mathbf{k}) = d_k\)
Why \(\sqrt{d_k}\)? The variance argument
Assume \(q_i, k_i \sim \text{i.i.d.}\) with mean 0, variance 1. The dot product is:
\[ q \cdot k = \sum_{i=1}^{d_k} q_i \, k_i \]
Each term \(q_i k_i\) has: \(\;\mathbb{E}[q_i k_i] = 0\), \(\;\text{Var}(q_i k_i) = 1\)
By independence, the variance of the sum is:
\[ \text{Var}(q \cdot k) = \sum_{i=1}^{d_k} \text{Var}(q_i k_i) = d_k \]
So dot products grow as \(O(d_k)\). Dividing by \(\sqrt{d_k}\) restores unit variance:
\[ \text{Var}\!\left(\frac{q \cdot k}{\sqrt{d_k}}\right) = \frac{d_k}{d_k} = 1 \]
Recall: Multi-head attention and causal masking
Multi-head: Run \(h\) parallel attention operations with \(d_k = d_{model}/h\)
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O \]
Causal masking: Prevent attending to future tokens
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top + M}{\sqrt{d_k}}\right)V \]
\[ \text{where } M_{ij} = \begin{cases} 0 & j \leq i \\ -\infty & j > i \end{cases} \]
The decoder-only transformer block
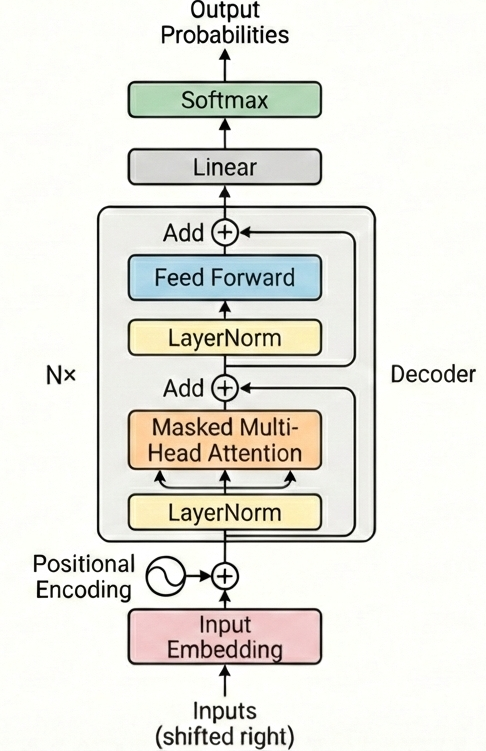
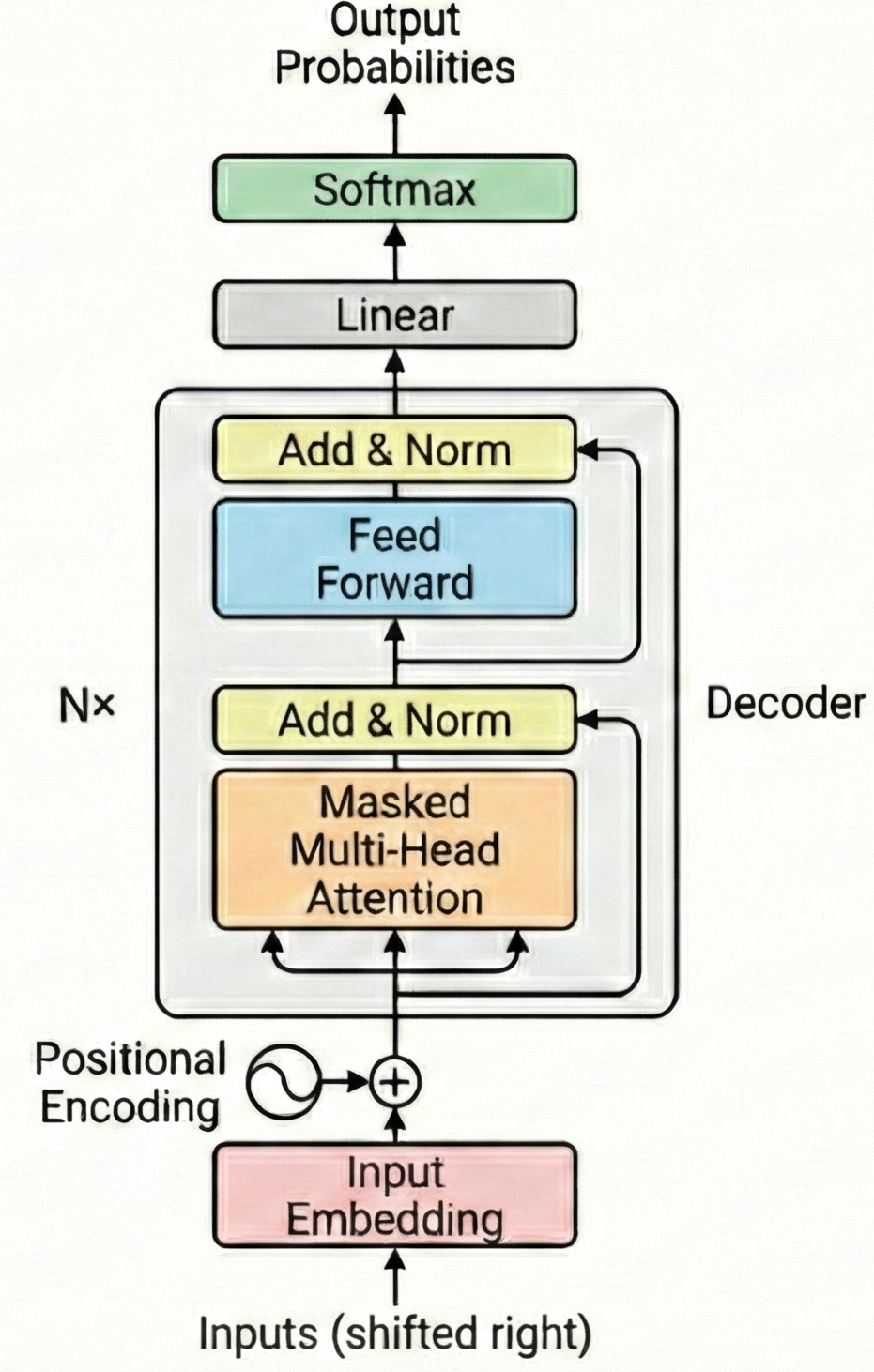
The Pre-Norm Decoder-only Transformer
Part 1: Implementing Self-Attention
Tensor dimensions throughout attention
Input: \(X \in \mathbb{R}^{B \times n \times d_{model}}\)
| Step | Operation | Shape |
|---|---|---|
| Input | X | (B, n_tok, d_model) |
| Project Q | Q = X @ W_Q | (B, n_tok, d_model) |
| Attention scores | A = Q @ K.T | (B, n_tok, n_tok) |
| Scale + Softmax | A = softmax(A / √d) | (B, n_tok, n_tok) |
| Output | O = A @ V | (B, n_tok, d_model) |
- B = batch size, n_tok = sequence length, d_model = embedding dimension
- The attention matrix is n_tok × n_tok—this is where O(n²) comes from
Attenion as a block diagram
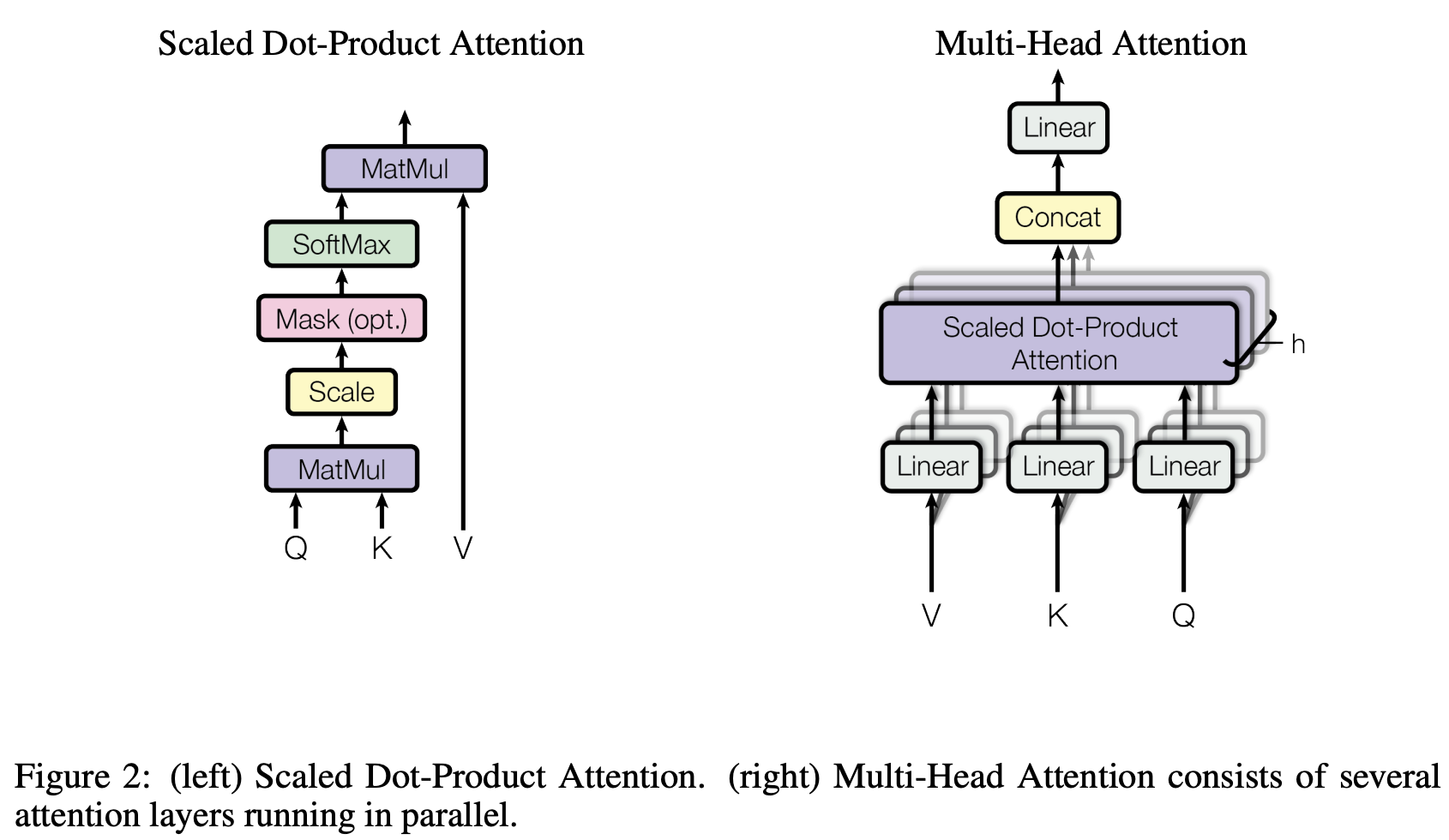
Multi-head attention — why split heads?
Problem: Single attention head has limited expressiveness
Solution: Run h parallel attention operations with smaller dimensions
1 attention operation
8 parallel attention ops
- Same total parameters: one 512-dim head ≈ eight 64-dim heads
- Each head can learn different relationship types
Part 2: What Makes a Language Model “Large”
A language model predicts probability distributions over tokens
Core function:
\[ P(x_t \mid x_1, \ldots, x_{t-1}; \theta) \]
(θ = parameters)
floor: 0.12
rug: 0.08
...
The model maps context → probability distribution over vocabulary
“Large” refers to both parameters and training data
| Model | Parameters | Training Tokens | Year |
|---|---|---|---|
| GPT-2 | 1.5B | 40B | 2019 |
| GPT-3 | 175B | 300B | 2020 |
| LLaMA-2 | 70B | 2T | 2023 |
| GPT-4 | ~1.8T* | ~13T* | 2023 |
Scale has grown ~1000× in 4 years
The three-stage training pipeline
Weeks of compute
Hours of compute
Days of compute

Slide from Andrej Karpathy: State of GPT
Part 3: Pretraining at Scale
The pretraining objective: predict the next token
Causal Language Modeling (CLM) loss:
\[ \mathcal{L}(\theta) = -\sum_{t=1}^{T} \log P_\theta(x_t \mid x_1, \ldots, x_{t-1}) \]
| Context | Target | Loss contribution |
|---|---|---|
| <bos> | The | −log P(The | <bos>) |
| The | quick | −log P(quick | The) |
| The quick | brown | −log P(brown | The quick) |
| The quick brown | fox | −log P(fox | The quick brown) |
| The quick brown fox | jumps | −log P(jumps | ...) |
Self-supervision: the data labels itself
Key insight: The structure of language provides free supervision at massive scale
Next-token prediction implicitly learns many skills
The simple objective captures complex structure

GPT-2 Paper
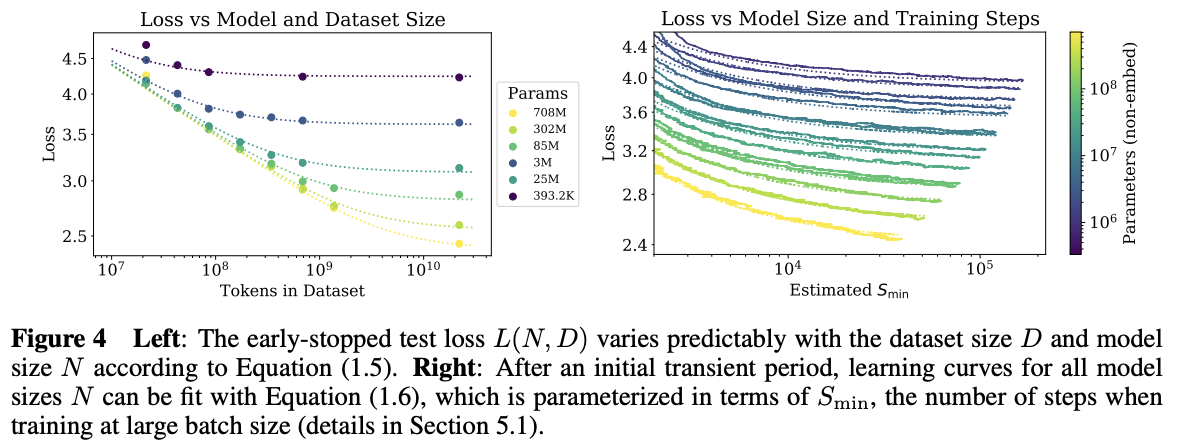
Scaling laws describe predictable improvement with resources
Empirical finding (Kaplan et al., 2020; Hoffmann et al., 2022):
\[ L(N, D) \approx \left(\frac{N_c}{N}\right)^{\alpha_N} + \left(\frac{D_c}{D}\right)^{\alpha_D} + L_\infty \]
Loss decreases as a power law in each resource
Scaling law curves (Kaplan et al., 2020)
Chinchilla scaling: balance parameters and data
Key insight (Hoffmann et al., 2022):
For a fixed compute budget, there’s an optimal ratio:
\[ N_{\text{opt}} \propto C^{0.5}, \quad D_{\text{opt}} \propto C^{0.5} \]
Rule of thumb: Train on ~20 tokens per parameter
CSE 447/517 26wi - NLP