Interpretability: From Mechanistic Foundations to Practice
2026-02-26
Sources & Objectives
Key References: Elhage et al. (2021) — Transformer Circuits; Olsson et al. (2022) — Induction Heads; Bricken et al. (2023) — Monosemanticity; Templeton et al. (2024) — Scaling Monosemanticity; nostalgebraist (2020) — Logit Lens
By the end of this lecture, you will be able to:
- Trace a computation through zero-, one-, and two-layer transformer circuits
- Apply the logit lens and sparse autoencoders to inspect model internals at scale
- Distinguish representational evidence (probes) from causal evidence (patching)
- Evaluate when mechanistic understanding is necessary vs. when behavioral testing suffices
- Honestly assess what interpretability can and cannot deliver today
This course builds an LLM engineering toolkit across six dimensions
What question are you actually asking?
Three levels of interpretability questions, from surface to mechanism:
This lecture builds bottom-up: start from mechanisms (circuits), develop scaling tools (probes, SAEs), then ask what practice demands.
Part 1: Mechanistic Foundations
From tokens to circuits
We start at the simplest possible transformer computation — no attention, no MLPs — and build toward multi-layer circuits. Each step adds exactly one new mechanism.
Zero-layer circuits: What does a transformer predict with no computation?
The simplest “circuit” — skip all attention heads and MLPs, go directly from input to output:
\(W_U\): unembedding matrix
\(x\): one-hot input token
| Input → | the | cat | sat | on |
|---|---|---|---|---|
| Top prediction | cat | is | on | the |
Single-layer circuits: How does one attention head transform the zero-layer predictions?

Source: Elhage et al., “A Mathematical Framework for Transformer Circuits” (2021)
Single-layer circuits: Mathematical reformulation
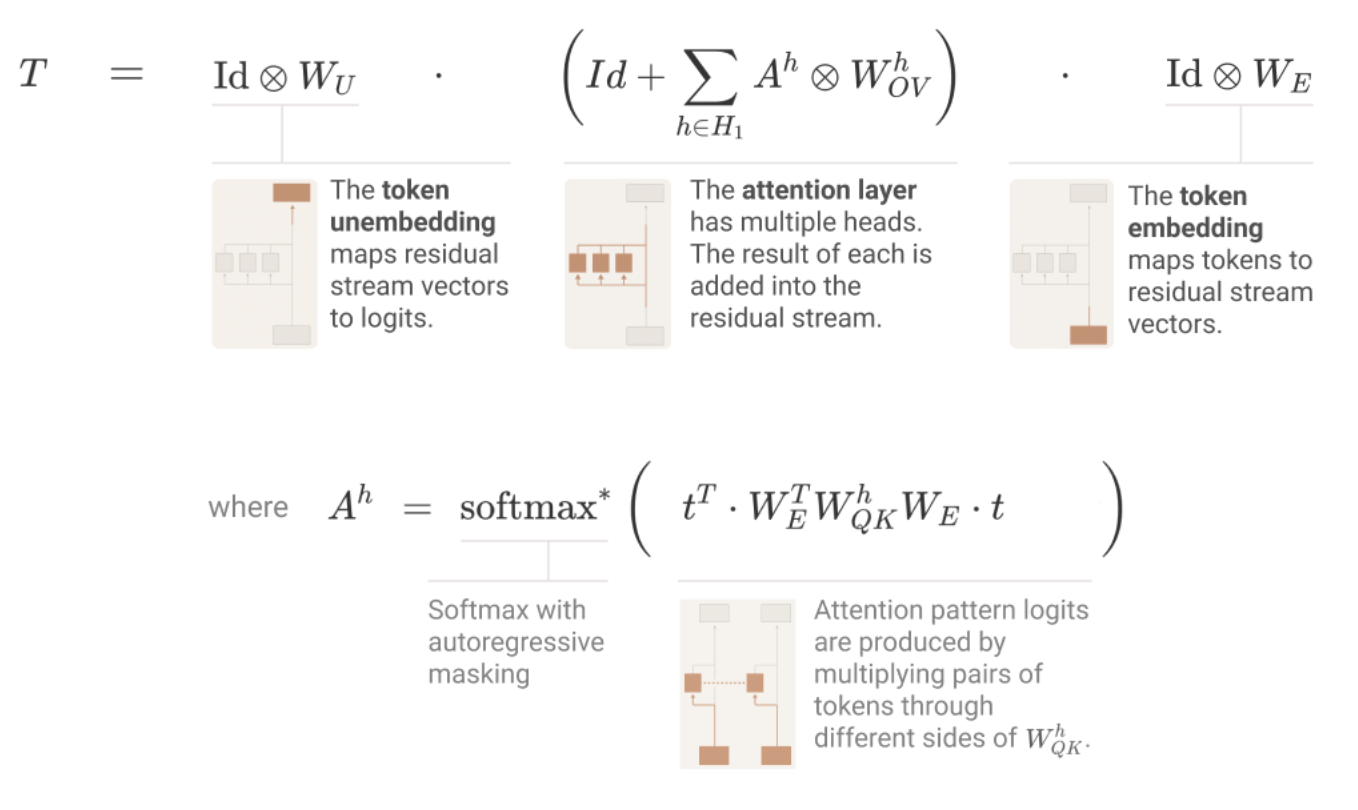
Source: Elhage et al., “A Mathematical Framework for Transformer Circuits” (2021)
Single-layer circuits: Mathematical reformulation (cont.)

Source: Elhage et al., “A Mathematical Framework for Transformer Circuits” (2021)
Splitting attention head terms into QK and OV circuits
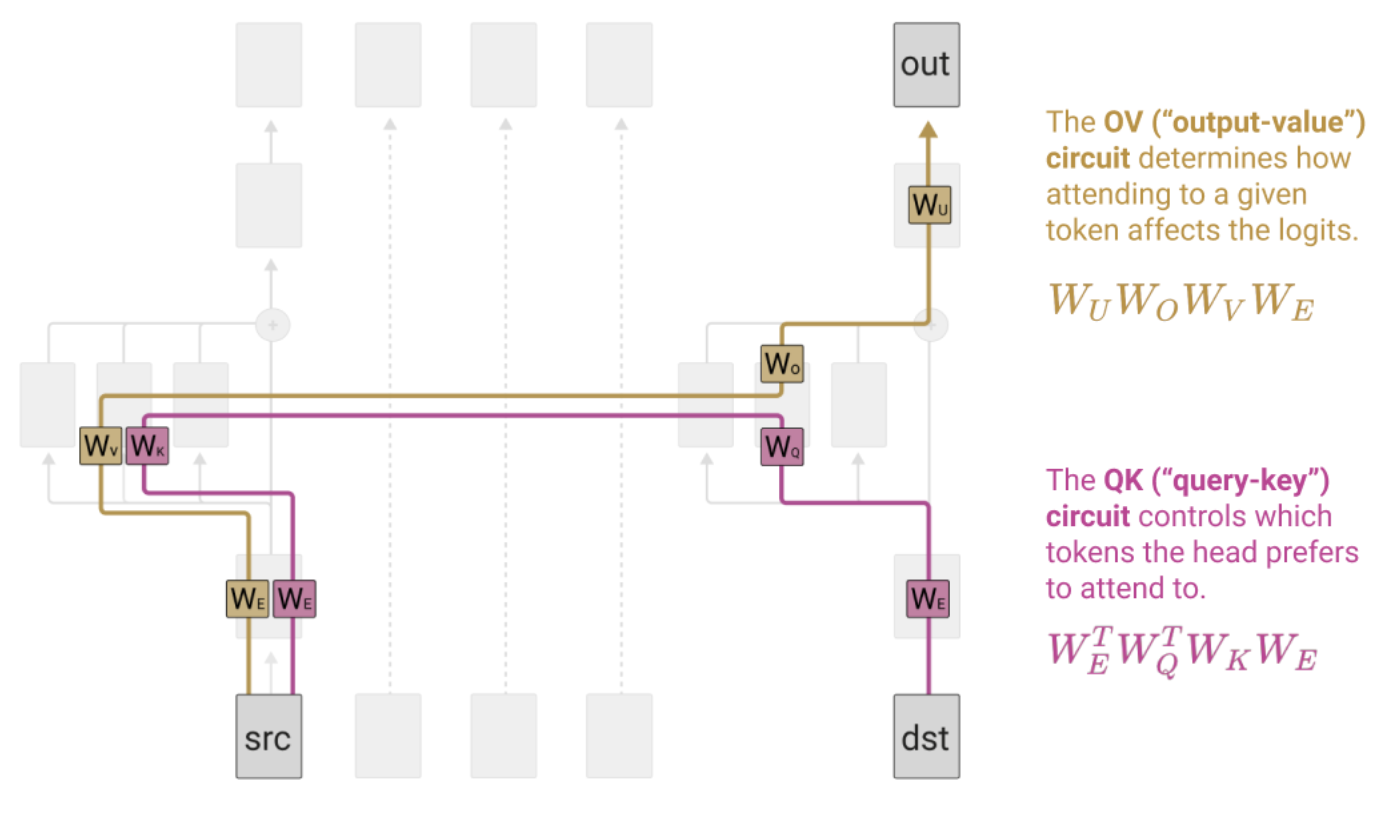
Source: Elhage et al., “A Mathematical Framework for Transformer Circuits” (2021)
QK and OV circuits: The atomic units of attention heads
Each attention head decomposes into two independent circuits:
Induction heads and name movers: One-layer circuit motifs
The induction head circuit — the mechanistic basis of in-context learning:
Activity: Compute a zero-layer prediction
Pair Activity (2 min)
Given this (simplified) bigram table from \(W_U^T W_E\):
| Input ↓ / Output → | the | cat | sat | on |
|---|---|---|---|---|
| the | 0.1 | 2.4 | 0.8 | 0.3 |
| cat | 1.1 | 0.2 | 2.7 | 0.6 |
| sat | 0.5 | 0.3 | 0.1 | 3.1 |
| on | 2.9 | 0.7 | 0.4 | 0.2 |
- What does the zero-layer model predict after “the”? After “sat”?
- Why is this a useful baseline for understanding what attention heads add?
Two-layer composition: How circuits chain together
When one head’s output becomes another head’s input, three types of composition arise:
Example: The induction circuit is K-composition — the previous-token head writes to the residual stream, and the induction head reads it via its key, changing which positions match the current query.
The residual stream: A shared communication bus
- The residual stream is a high-dimensional shared workspace — every layer reads from it and writes back to it
- Each layer’s contribution is additive: \(x_{out} = x_{in} + \text{Attn}(x) + \text{MLP}(x)\)
- This additive structure is why we can decompose the model into circuits at all
The combinatorial wall: Why circuit analysis doesn’t simply scale
As models grow, the number of possible interaction paths explodes:
| Model | Layers | Heads/Layer | Total Heads | 2-Head Paths | All Paths |
|---|---|---|---|---|---|
| GPT-2 Small | 12 | 12 | 144 | ~10K | ~106 |
| GPT-2 XL | 48 | 25 | 1,200 | ~700K | ~1026 |
| Llama 70B | 80 | 64 | 5,120 | ~13M | ~10100+ |
- You cannot enumerate all circuits in a frontier model — the combinatorics are astronomical
- This motivates every tool in Part 2: we need methods that bypass exhaustive circuit search
Part 2: Scaling Tools
From circuits to scalable methods
Since we can’t trace every circuit by hand, we need tools that summarize internal computation. Each tool trades off fidelity for scalability.
The logit lens: Reading the residual stream as vocabulary predictions
Idea (nostalgebraist, 2020): At every layer, project the residual stream through the unembedding matrix to see what the model would predict if it stopped here.
Tuned lens: Fixing the logit lens’s calibration problem
- Tuned lens gives better-calibrated predictions at every layer, especially in early/middle layers
- Reveals a cleaner picture of when the model forms its predictions
Probing classifiers: What is linearly decodable from representations?
Setup: Train a linear classifier on frozen embeddings: \(y_i = \text{softmax}(Wh_i + b)\)
Activity: Sketch a logit lens for “The Eiffel Tower is in”
Individual + Compare (3 min)
For the input “The Eiffel Tower is in”, sketch what you think the logit lens top-1 prediction would be at each layer:
| Layer | Embedding | Layer 2 | Layer 6 | Layer 10 | Layer 12 | Final |
|---|---|---|---|---|---|---|
| Top-1 | ? | ? | ? | ? | ? | ? |
| Confidence | low | ? | ? | ? | ? | high |
- Fill in your guesses, then compare with a neighbor
- At what layer do you think “Paris” first appears as the top prediction?
Sparse autoencoders decompose superposed features into interpretable units
Superposition problem: Models encode more features than they have dimensions, causing features to overlap.
SAE objective — reconstruct activations with sparse features:
\[\mathcal{L} = \| h - \hat{h} \|_2^2 + \lambda \| z \|_1\]
where \(\hat{h} = W_{dec} \cdot \text{ReLU}(W_{enc} \cdot h + b_{enc}) + b_{dec}\) and \(z\) are the encoder activations.
- Reconstruction term (\(L_2\)): features should faithfully reconstruct the original activation
- Sparsity penalty (\(L_1\)): only a few features should be active for any given input
- Bricken et al. (2023): thousands of interpretable features from Claude’s MLP layers
- Templeton et al. (2024): scaled to Claude 3 Sonnet — millions of interpretable features
Activation patching and path patching: Causal tools for circuit discovery
Activation patching: Replace one activation with a value from a different context; measure the output change.
Path patching extends this to trace specific information routes:
- Path patching was critical for the IOI circuit discovery (Wang et al., 2022) — identified which heads read from which other heads
The evidence hierarchy: Not all interpretability evidence is equal
Part 3: Bridging to Practice
From understanding to deployment
Mechanistic knowledge is only useful if it changes what you do. This section asks: when does circuit-level understanding actually help in practice?
Steering vectors: Editing model behavior via representations
Core idea: Find a direction in activation space that corresponds to a concept, then add or subtract it at inference time.
\[v_{\text{steer}} = \text{mean}(h_{+}) - \text{mean}(h_{-})\]
where \(h_+\) are activations from positive examples and \(h_-\) from negative examples.
2. Collect activations on "deceptive" prompts → \(h_-\)
3. Difference of means = steering direction
\(\alpha > 0\): amplify the concept
\(\alpha < 0\): suppress the concept
No retraining required — inference-time only
Examples from representation engineering (Zou et al., 2023):
- Honesty/deception, positive/negative sentiment, refusal/compliance
- Works across many prompts, not just the training examples
Mechanistic red teaming: Using circuits to find failure modes
| Traditional Red Teaming | Mechanistic Red Teaming | |
|---|---|---|
| Approach | Craft adversarial inputs, observe outputs | Identify vulnerable circuits, predict failure modes |
| Evidence | Behavioral (found an exploit) | Mechanistic (understand why it fails) |
| Scalability | Scales with human effort / automation | Currently limited to smaller models / specific circuits |
| Fixes | Patch the input (filter, RLHF) | Patch the circuit (ablation, steering, editing) |
| Maturity | Production-ready | Research stage |
- The promise: if you understand why a model fails, you can anticipate new failure modes, not just patch known ones
- The reality: mechanistic red teaming currently works best on targeted, well-defined behaviors (bias in specific circuits, knowledge errors in specific MLPs)
Activity: When is mechanistic understanding necessary?
Pair Debate (3 min)
For each scenario, argue: is behavioral testing sufficient, or do you need mechanistic understanding?
For each: What could go wrong? What level of evidence (from the hierarchy) do you need?
Behavioral vs. mechanistic evidence: What does deployment require?
Production interpretability: What ships today vs. what’s still research
The production interpretability stack
A realistic 4-step workflow for incorporating interpretability into a deployed LLM system:
Part 4: Honest Assessment
Where are we, really?
Interpretability has made remarkable progress. It also has fundamental unsolved problems. This section is about being honest about both.
What works today
Activity: Works / Open / Wishful Thinking
Rapid Vote — Whole Class (2 min)
For each claim, vote: Works (solid evidence), Open (active research, unclear), or Wishful (no good evidence yet).
(Show of hands for each. Instructor reveals suggested answers after all votes.)
Open problems: What the field hasn’t solved
The path forward
- Circuit analysis identifies a bias mechanism → design targeted behavioral tests
- SAE features flag anomalous activations → trigger deeper investigation
- Probing reveals unexpected encoding → validate with causal intervention
- LLMs label SAE features (Bills et al., 2023)
- Automated circuit discovery (Conmy et al., 2023 — ACDC)
- Scalable oversight: models audit each other's internals
Summary: Key Takeaways
- Circuits (zero/one/two-layer) provide the mathematical foundation — the residual stream’s additive structure makes decomposition possible
- The combinatorial wall is real — scaling from GPT-2 to frontier models requires fundamentally new approaches
- Scaling tools (logit lens, probes, SAEs, patching) trade fidelity for tractability — know where each sits on the evidence hierarchy
- Causal evidence (patching) is stronger than representational evidence (probes) is stronger than behavioral evidence (testing) — but each has its place
- Practice demands honesty — production systems mostly use behavioral methods; mechanistic analysis is reserved for when you need to know why
- The path forward is hybrid: mechanistic insights guiding behavioral tests, with automation closing the scalability gap
Further Reading
References & Resources
- Elhage et al., “A Mathematical Framework for Transformer Circuits” (Anthropic, 2021) — The foundational paper on QK/OV circuits and composition
- Olsson et al., “In-context Learning and Induction Heads” (Anthropic, 2022) — Mechanistic explanation of in-context learning
- Bricken et al., “Towards Monosemanticity” (Anthropic, 2023) — Sparse autoencoders for feature extraction
- Templeton et al., “Scaling Monosemanticity” (Anthropic, 2024) — SAEs at Claude 3 Sonnet scale
- nostalgebraist, “interpreting GPT: the logit lens” (2020) — The original logit lens blog post
- Wang et al., “Interpretability in the Wild: IOI” (2022) — Most complete circuit reverse-engineering to date
- Belrose et al., “Eliciting Latent Predictions with the Tuned Lens” (2023) — Calibrated layer-wise predictions
- Zou et al., “Representation Engineering” (2023) — Steering vectors and concept directions
- Conmy et al., “Towards Automated Circuit Discovery” (2023) — ACDC for scalable circuit finding
Coming Up Next
March 3: Evaluation and Benchmarking
- How do we measure what models can and can’t do?
- Contamination, data leakage, and the benchmark treadmill
- Designing evaluations that actually inform deployment decisions