Prompting and Reasoning
2026-02-17
Sources
Content derived from: J&M Ch. 7 (Large Language Models)
Today’s Lecture:
- In-context learning: zero-shot and few-shot prompting
- Chain-of-thought and structured reasoning strategies
- Structured prompting for controlled outputs
- Agentic workflows: planning, tool use, and failure modes
Learning Objectives
By the end of this lecture, you will be able to:
- Explain how in-context learning enables task adaptation without parameter updates
- Design effective zero-shot and few-shot prompts following principled design guidelines
- Apply chain-of-thought prompting and compare advanced reasoning strategies
- Use structured prompting to enforce schema-constrained outputs
- Describe agentic LLM architectures and identify their failure modes
Roadmap for our Final Push
Running Example: Medical Triage Assistant
Throughout this lecture, we’ll develop prompts for a concrete scenario: a medical triage assistant that helps patients describe symptoms and routes them to appropriate care.
Goal: Classify patient urgency (emergency / urgent / routine), suggest department
Constraints: Must never diagnose, always recommend professional evaluation, handle anxiety sensitively
Key challenge: Get this right with prompting alone — no finetuning budget
- As we cover each prompting strategy, we’ll ask: how would you prompt the triage assistant?
Part 1: In-Context Learning
State Change: Learning Without Training
Finetuning adapts model weights. In-context learning adapts model behavior through the prompt alone, keeping all parameters frozen.
In-context learning (ICL) enables task adaptation by conditioning on natural language prompts
The model processes a prompt \(p\) and input \(x\) to produce output \(y\) with frozen weights \(\theta\):
\[ y = \mathrm{LLM}_\theta(p, x) \]
- The prompt acts as an inductive bias, tapping into latent knowledge from pretraining
Zero-shot prompting provides only a task description, while few-shot adds demonstrations
| Prompt Type | What the Model Sees | Example |
|---|---|---|
| Zero-shot | Task description only | Translate to French: 'cat' |
| Few-shot | k input-output demonstrations | cat → chat, dog → chien, house → ? |
- Few-shot prompting provides \(k\) exemplars so the model infers the pattern from demonstrations
- The model is not updating parameters — it performs statistical pattern completion over the context
Prompt wording, formatting, and example order significantly affect model predictions
The output distribution is sensitive to prompt structure:
\[ P(y \mid x, p_1) \neq P(y \mid x, p_2) \quad \text{if} \quad p_1 \neq p_2 \]
Prompt sensitivity is real: Zhao et al. (2021) showed that simply reordering few-shot examples can swing GPT-3 accuracy from near-chance to near-SOTA on the same benchmark — a 30+ percentage point difference from permutation alone.
- Diverse, balanced exemplars calibrate outputs and reduce unwanted bias
Small prompt changes produce dramatically different triage decisions
Think-Pair-Share: Choosing a Prompting Strategy
For our triage assistant, would you use zero-shot or few-shot prompting? Consider:
- Latency: How fast must the response be? (few-shot uses more tokens)
- Accuracy: How much does task performance improve with examples?
- Label space: Is {EMERGENCY, URGENT, ROUTINE} clear enough without examples?
- Calibration: Do you need the model to express uncertainty?
Discuss with a neighbor for 2 minutes, then share your recommendation.
Part 2: Chain-of-Thought and Structured Reasoning
State Change: Beyond Direct Answers
Standard prompting asks for a final answer. Chain-of-thought prompting elicits intermediate reasoning steps, dramatically improving performance on complex tasks.
Chain-of-thought prompting decomposes complex tasks into explicit intermediate steps
CoT biases the model toward generating a reasoning trace rather than a single direct answer:
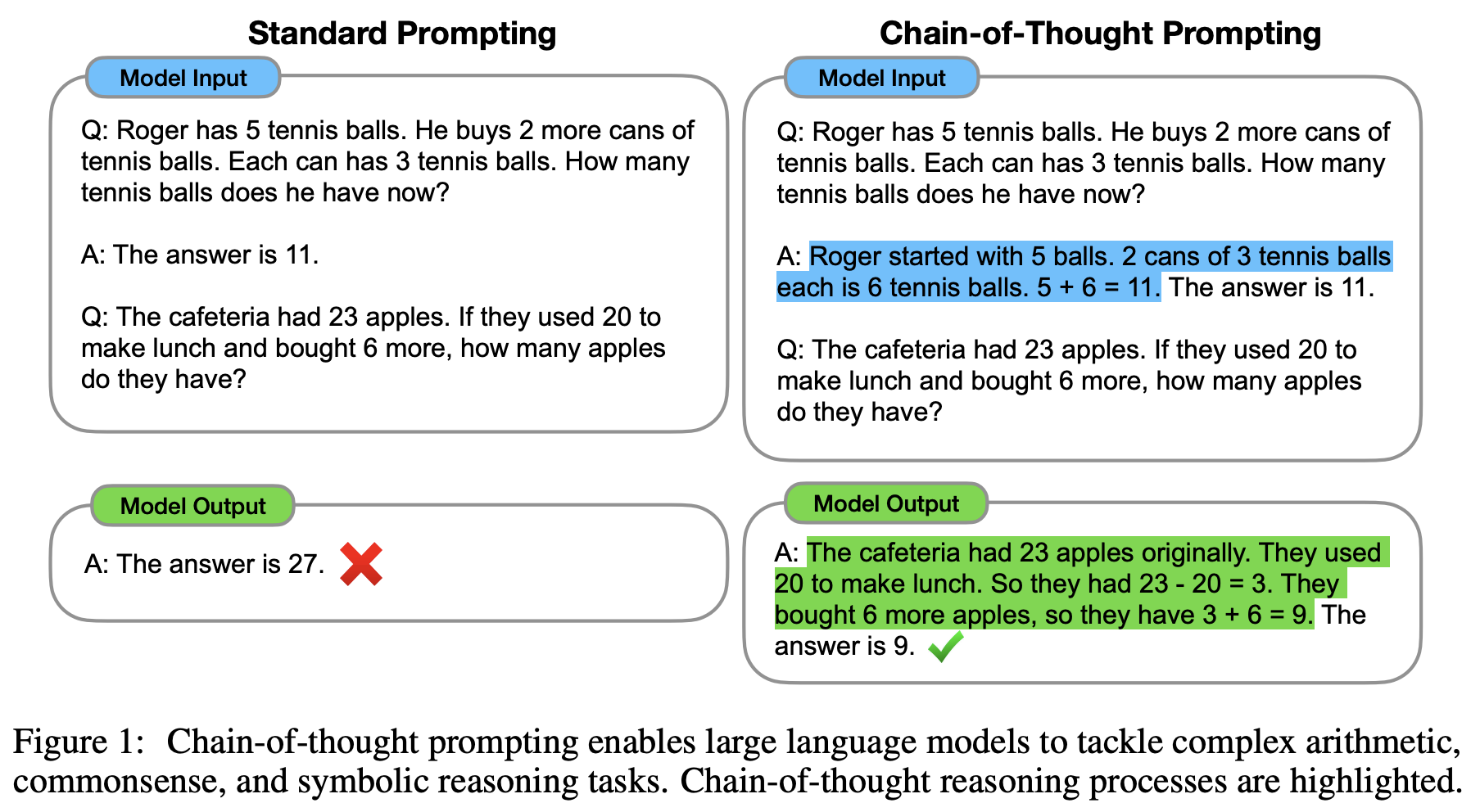
Standard vs. chain-of-thought prompting from Wei et al. (2022)
- The model breaks complex problems into tractable subproblems, avoiding shallow heuristics
- CoT is most effective for tasks requiring multi-step logic: arithmetic, symbolic reasoning, multi-hop QA
Zero-shot CoT adds a trigger phrase while few-shot CoT provides worked examples
- On GSM8K, GPT-3 accuracy rises from below 20% (direct) to over 50% with zero-shot CoT
- Even a single trigger phrase dramatically changes model behavior due to learned priors
Adding “Let’s think step by step” produces dramatic accuracy gains across reasoning tasks (Kojima et al., 2022)
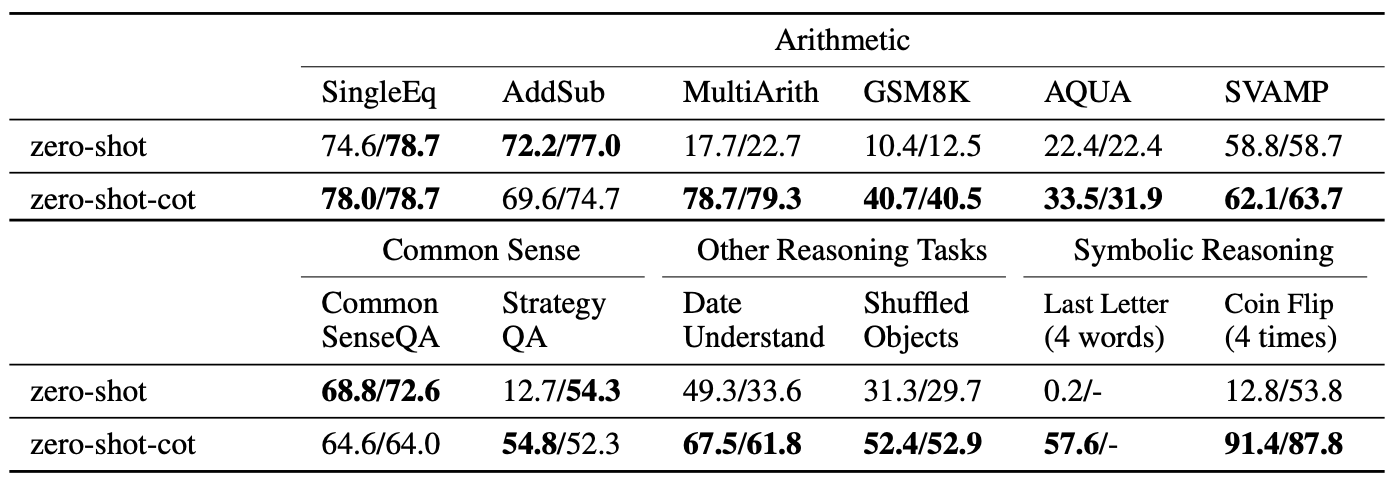
- A single phrase appended to the prompt consistently doubles accuracy on math reasoning benchmarks
- The effect is most pronounced on tasks requiring multi-step arithmetic
Chain-of-thought helps reasoning tasks but not simple pattern matching
- For our triage assistant: CoT helps when symptoms are ambiguous (“chest pain + shortness of breath + recent travel” requires reasoning about multiple possibilities)
GPT-4 and the Bar Exam
GPT-4 scored in the 90th percentile on the Bar Exam (vs. GPT-3.5’s 10th percentile). Takeaway: Benchmarks can overstate reasoning ability — multiple-choice format may not reflect true open-ended legal reasoning.
Self-consistency, tree-of-thought, and least-to-most extend basic chain-of-thought
- Self-consistency reduces stochasticity by aggregating over multiple reasoning chains
- These methods trade compute for accuracy — more reasoning paths yield more reliable answers
Tree-of-Thought explores multiple reasoning branches and backtracks from dead ends
- Unlike linear CoT, ToT can backtrack from unpromising paths and explore alternatives
- The LLM serves as both the generator (proposing steps) and the evaluator (scoring them)
Choosing a reasoning strategy involves compute-accuracy tradeoffs
| Strategy | Compute Cost | Robustness | Best For |
|---|---|---|---|
| Basic CoT | 1× | Low | Simple multi-step problems |
| Self-Consistency | N× | High | When you need reliable answers (triage!) |
| Tree-of-Thought | N×M× | Highest | Creative/open-ended exploration |
| Least-to-Most | K× | Medium | Hierarchical decomposition |
- For our triage assistant, self-consistency is the right choice: sample 5 triage classifications, take the majority — a wrong classification has real consequences
Concept Check
Why does self-consistency improve over a single chain-of-thought? Under what conditions might it fail? Think about the relationship between answer diversity and aggregation quality.
Discussion (2 min)
Consider a multi-hop science question: “What element has the highest electronegativity, and what compounds does it commonly form?” Would you use basic CoT, self-consistency, or least-to-most prompting? Why?
Hallmark Discoveries in Prompting and Reasoning
Part 3: Structured Prompting Techniques
State Change: Controlling Output Format
Reasoning strategies improve answer quality. Structured prompting goes further by constraining the format of model outputs, enabling integration with downstream systems.
Structured prompting constrains LLM outputs to machine-readable formats like JSON or XML
By specifying output schemas, we reduce output entropy and enable robust downstream parsing:
\[ f_{\text{LLM}}(x; P) \in \mathcal{S} \]
where \(\mathcal{S}\) is the set of valid outputs (e.g., all well-formed JSON objects).
- Schema-constrained prompts support automation: API calls, data validation, pipeline integration
Prompt templates and role instructions reinforce consistent output structure
- System instructions (role prompts) establish context and reinforce schema adherence
- Clear templates improve reliability across repeated calls and diverse inputs
The generate-validate-retry pattern ensures reliable structured outputs
"reasoning": "string",
"recommended_department": "string",
"disclaimer": "Always seek professional medical advice"}
Retrieval-augmented prompting injects external context to ground LLM responses in facts
\[ \text{Prompt}(q) = \text{concat}\left(\mathcal{R}(q),\ q\right) \]
- RAG mitigates knowledge cutoff by dynamically providing up-to-date or domain-specific information
- Key prompting pattern for RAG: inject evidence, instruct to cite, handle context limits
- We’ll cover RAG architecture in depth in a later lecture — today, focus on how the prompt changes
Concept Check
A biomedical QA system retrieves 20 PubMed abstracts for each query, but the LLM’s context window is 4,096 tokens. What strategies could you use to handle this? What are the trade-offs?
Part 4: Agentic Workflows
State Change: From Answering to Acting
Prompting strategies so far produce text. Agentic workflows enable LLMs to reason, plan, and invoke external tools to complete tasks in the real world.
The ReAct framework interleaves reasoning traces with tool-calling actions
LLMs alternate between generating intermediate thoughts and invoking external tools:
\[ \pi: (x, h) \rightarrow (r, a) \]
where \(r\) is a reasoning step, \(a\) is an action (API/tool call), and \(h\) is the interaction history.

ReAct framework comparison from Yao et al. (2023): reasoning-only vs. action-only vs. ReAct
- Tool calls are generated as output tokens, extending LLM capacity beyond language modeling
ReAct grounds each reasoning step in observable actions and environmental feedback
- ReAct agents outperform pure reasoning (CoT) and pure acting (tool-only) approaches by combining both
- The observation step grounds the model in real data, reducing hallucination
Agents combine planning, tool use, and reflection — depth in Feb 24
- Planning: Decompose goals into sub-tasks with explicit success criteria
- Tool use: Invoke APIs, run code, query databases — covered in depth Feb 24
- Observe-act loop: Agents iterate on environment feedback (ReAct pattern)
For our triage assistant, a simple agent loop might:
- classify urgency
- look up relevant medical guidelines via RAG
- verify the classification is consistent with guidelines
Agentic pipelines face compounding errors, hallucination, and prompt injection attacks
For a pipeline of \(n\) steps where each step has error probability \(p_i\):
\[ P_{\text{failure}} = 1 - \prod_{i=1}^n (1 - p_i) \]
- Reliability decreases exponentially with pipeline depth, even when individual step error rates are low
Concept Check
If each step in a 5-step agentic pipeline has a 10% error rate, what is the overall failure probability? What does this imply about designing agentic systems?
Summary: Prompting and Reasoning – Key Takeaways
In-context learning enables task adaptation through prompts alone, with no parameter updates — the prompt serves as an inductive bias over frozen weights
Prompt design matters: wording, formatting, and example order significantly affect model behavior; principled prompt engineering is essential
Chain-of-thought prompting elicits step-by-step reasoning, yielding large accuracy gains on arithmetic, logic, and multi-hop tasks
Advanced strategies (self-consistency, tree-of-thought, least-to-most) trade additional compute for more reliable reasoning
Structured prompting constrains outputs to machine-readable formats, enabling integration with production systems
Agentic workflows extend LLMs from text generators to planners and actors, but face compounding errors, hallucination, and prompt injection risks
3 prompting heuristics you can apply tomorrow:
- Be explicit: Specify role, format, constraints, and edge case handling in every prompt
- Test variants: Run 3+ prompt phrasings and measure variance before committing
- Match compute to stakes: Use self-consistency for high-stakes decisions, basic CoT for everyday tasks
Coming Up Next
Finetuning & Adaptation (Feb 19)
When prompting hits its limits — insufficient domain knowledge, inconsistent behavior, or the need for persistent style changes — we turn to training-time adaptation.
- Full finetuning vs. parameter-efficient methods (LoRA, adapters)
- Instruction tuning and RLHF/DPO alignment
- Choosing between prompting, finetuning, and RAG